在当今大数据与人工智能技术蓬勃发展的时代,一系列基础且强大的算法构成了智能系统的核心骨架。其中,k近邻(k-Nearest Neighbors, k-NN)算法以其直观、非参数的特性,不仅在分类任务中广为人知,其回归模型变体——k近邻回归(k-NN Regression)——同样在预测分析领域扮演着重要角色。本文将探讨k近邻回归模型的原理、其在大数据环境下的挑战与优化,并阐述其在人工智能基础软件开发中的实践价值。
一、k近邻回归模型:原理与核心思想
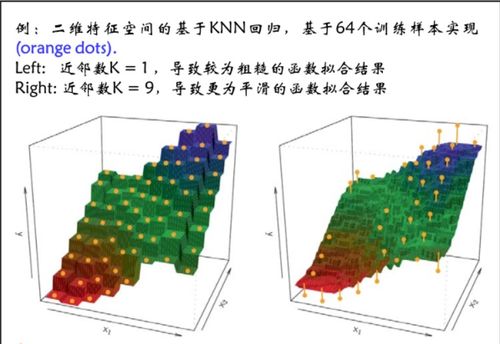
k近邻回归是一种基于实例的学习方法,它不试图构建一个显式的全局模型,而是“记住”所有的训练数据。当需要对一个新样本进行预测时,算法会在训练集中寻找与该样本最相似的k个邻居(通常使用欧氏距离、曼哈顿距离等度量),然后通过对这k个邻居的目标变量值(通常是连续值)取平均值(或加权平均)来预测新样本的值。
其核心公式可简化为:
> ŷ = (1/k) * Σ y_i (对于简单平均)
其中,ŷ 是预测值,y_i 是第i个邻居的目标值。这种“局部平均”的思想使得k近邻回归对数据局部结构有很好的拟合能力,尤其适合那些输入变量与输出变量之间关系复杂、非线性的场景。
二、大数据背景下的挑战与演进
在传统小数据集上,k近邻回归简单有效。面对大数据环境,其面临显著挑战:
- 计算复杂度高:预测时需要计算新样本与所有训练样本的距离,时间复杂度为O(n),对于海量数据(n极大)实时性差。
- 存储成本大:需要存储全部训练数据,内存消耗高。
- 维度灾难:在高维特征空间中,距离度量可能失效,所有点之间的距离变得相似,导致模型性能下降。
为应对这些挑战,业界发展出多种优化策略,这些也正是人工智能基础软件开发需要集成的关键能力:
- 近似最近邻搜索(ANN)算法:如KD-Tree、Ball Tree、局部敏感哈希(LSH)等,通过构建索引结构,以牺牲少量精度为代价,大幅提升近邻搜索速度。
- 降维技术:在主成分分析(PCA)、t-SNE等技术的预处理下,减少特征维度,缓解维度灾难。
- 分布式计算框架集成:利用Spark MLlib、Flink ML等大数据计算框架,将数据和距离计算并行化,实现可扩展的k近邻处理。
三、在人工智能基础软件开发中的实践价值
k近邻回归模型作为一种基础算法,其实现与优化是衡量一个AI软件开发框架或库是否成熟、高效的标准之一。它在基础软件开发中的应用价值体现在:
- 构建标准化机器学习库:成熟的AI开发框架(如Scikit-learn、TensorFlow、PyTorch等)均提供高效、稳定的k近邻回归实现,支持多种距离度量、加权方案和搜索算法,为上层应用提供可靠的“积木”。
- 服务于更复杂模型的组件:在集成学习、半监督学习或某些深度学习模型的预处理/后处理阶段,k近邻回归可以作为有效的插补缺失值、平滑输出或生成伪标签的基础工具。
- 原型开发与可解释性:由于其原理直观,k近邻回归常被用于快速原型验证。其预测结果可以通过展示“邻居”来进行解释,这符合当前对AI可解释性的迫切需求,有助于开发具有透明度的AI系统。
- 教育与实践的桥梁:在AI教学和入门级开发工具中,实现一个k近邻回归模型是理解机器学习基本概念(如距离、超参数k、过拟合/欠拟合)的绝佳实践项目,有助于培养开发者的算法思维。
四、开发实践要点
在进行相关软件开发时,开发者需重点关注:
- 算法接口设计:提供清晰的fit/predict接口,支持样本权重、多输出回归等扩展功能。
- 性能优化:针对大数据场景,默认集成ANN算法或提供便捷的插件接口。
- 与数据处理流水线无缝集成:能够与特征缩放、编码、管道(Pipeline)等组件协同工作。
- 自动化与自动化机器学习(AutoML):提供超参数k和距离度量的自动搜索与优化功能,降低使用门槛。
###
k近邻回归模型,作为从大数据中挖掘价值的经典工具之一,其生命力在于简单性与扩展性的结合。在人工智能基础软件开发中,深入理解和高效实现此类基础模型,不仅是构建强大AI系统的技术基石,也是推动AI技术民主化、赋能各行各业智能化转型的关键一步。随着硬件算力的提升和算法的持续创新,k近邻回归及其思想必将在边缘计算、实时预测等新兴场景中焕发新的光彩。